
Xiaomi ได้ก้าวเข้าสู่ตลาด LLM หรือโมเดลภาษาขนาดใหญ่ด้วย MiMo-7B ซึ่งเป็นระบบ AI โอเพนซอร์สที่เปิดให้สาธารณชนใช้งานเป็นรุ่นแรก โดย MiMo-7B สร้างขึ้นโดย Big Model Core Team ที่เพิ่งตั้งขึ้นใหม่ มุ่งเน้นไปที่งานที่ต้องใช้เหตุผลเป็นหลัก และมีประสิทธิภาพเหนือกว่าคู่แข่งอย่าง OpenAI และ Alibaba ในด้านการใช้เหตุผลทางคณิตศาสตร์และการสร้างโค้ด
MiMo-7B เป็นโมเดลที่มีพารามิเตอร์ 7 พันล้านโมเดล แม้ว่าจะมีขนาดเล็กกว่า LLM ชั้นนำส่วนใหญ่อย่างเห็นได้ชัด แต่ Xiaomi อ้างว่ามีประสิทธิภาพเทียบเท่ากับระบบที่ใหญ่กว่า เช่น o1-mini ของ OpenAI และ Qwen-32B-Preview ของ Alibaba ซึ่งทั้งสามระบบรองรับการใช้เหตุผลด้วย AI ได้
โครงสร้างหลักของ Xiaomi MiMo-7B
โครงสร้างหลักของ MiMo-7B คือระบบการเตรียมตัวก่อนการเทรนนิ่งที่เข้มงวด โดย Xiaomi กล่าวว่าได้รวบรวมชุดข้อมูลที่เข้มข้นของโทเค็นการใช้เหตุผล 200 พันล้านชุด และป้อนโทเค็น 25 ล้านล้านชุด ให้กับโมเดลในสามขั้นตอนการฝึกอบรม
บริษัทใช้เป้าหมายการคาดการณ์โทเค็นหลายตัวแทนการคาดการณ์โทเค็นถัดไปแบบมาตรฐาน โดยอ้างว่าจะช่วยลดเวลาในการอนุมานโดยไม่กระทบต่อคุณภาพของเอาต์พุต
นอกจากนี้ กระบวนการหลังการเทรนนิ่งเกี่ยวข้องกับการผสมผสานเทคนิคการเรียนรู้เสริมและการปรับปรุงโครงสร้างพื้นฐาน ซึ่ง Xiaomi ใช้ขั้นตอนที่กำหนดเองที่เรียกว่า Test Difficulty Driven Reward เพื่อจัดการกับสัญญาณรางวัลเล็กน้อยซึ่งมักก่อกวนงาน RL ที่เกี่ยวข้องกับขั้นตอนที่ซับซ้อน รวมถึง Xiaomi ยังนำวิธีการ Easy Data Re-Sampling มาใช้เพื่อทำให้การเทรนนิ่งที่มีความเสถียรอีกด้วย
ในด้านโครงสร้างพื้นฐาน บริษัทได้สร้างระบบ Seamless Rollout เพื่อลดเวลาหยุดทำงานของ GPU ระหว่างการเทรนนิ่งและการตรวจสอบความถูกต้อง ผลลัพธ์อย่างน้อยตามตัวเลขภายในคือความเร็วในการเทรนนิ่งที่ดีขึ้น 2.29 เท่า และประสิทธิภาพการตรวจสอบความถูกต้องเพิ่มขึ้นเกือบ 2 เท่า
Rollout Engine ยังได้รับการออกแบบมาเพื่อรองรับกลยุทธ์การอนุมาน เช่น การทำนายโทเค็นหลายตัวในสภาพแวดล้อมแบบ vLLM อีกด้วย
MiMo-7B เป็นโอเพ่นซอร์ส
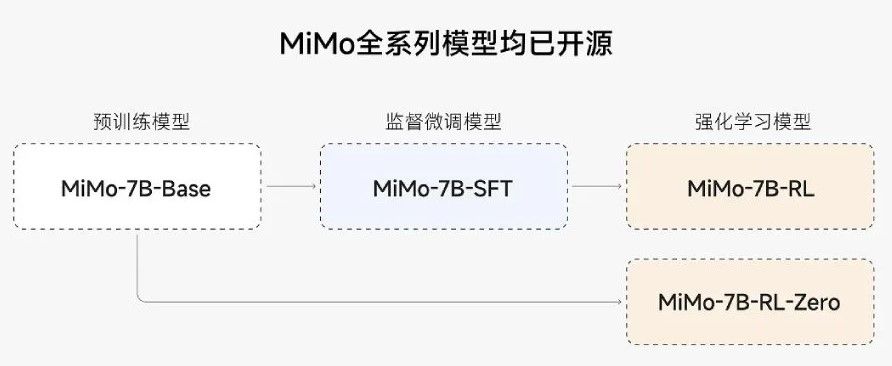
MiMo-7B มีเวอร์ชันที่เปิดใช้งานแบบสาธารณะอยู่ 4 เวอร์ชัน ได้แก่:
- Base: เวอร์ชันพื้นฐานที่เป็นโมเดลที่ผ่านการเทรนนิ่งมาแล้วล่วงหน้า
- SFT: เวอร์ชันที่ปรับแต่งด้วยข้อมูลที่ได้รับการกำกับดูแลมาแล้ว
- RL-Zero: เวอร์ชันที่เรียนรู้จากการเสริมแรงโดยเริ่มจากรุ่นพื้นฐาน
- RL: โมเดลที่ได้รับการขัดเกลาขึ้นจากเวอร์ชัน SFT ซึ่งกล่าวกันว่าให้ความแม่นยำสูงสุด
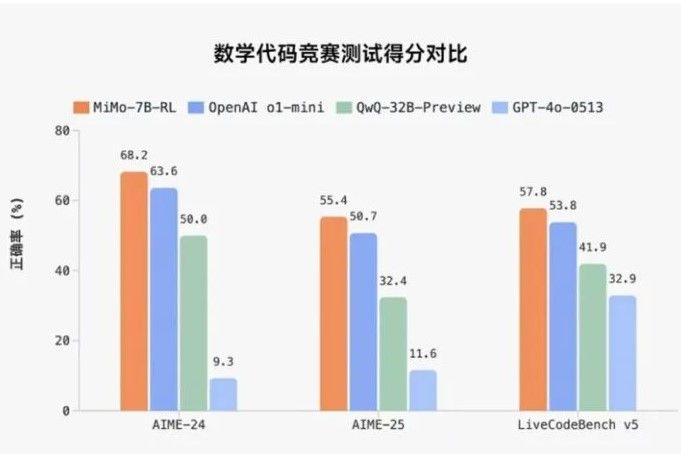
และ Xiaomi ยังมีคะแนนการทดสอบตามเกณฑ์มาตรฐานมาสนับสนุน โดยในทางคณิตศาสตร์ รายงานว่าเวอร์ชัน MiMo-7B-RL สามารถทำคะแนนได้ 95.8% ใน MATH-500 และมากกว่า 68% ในข้อมูลชุด AIME ปี 2024 และสำหรับการโค้ดดิ้ง เวอร์ชันนี้ทำคะแนนได้ 57.8% ใน LiveCodeBench v5 และเกือบ 50% ในเวอร์ชัน 6 นอกจากนี้ ยังมีงานความรู้ทั่วไปที่ครอบคลุมกว่า เช่น DROP, MMLU-Pro และ GPQA แม้ว่าคะแนนจะอยู่ที่ระดับกลางถึงสูง 50 คะแนนขึ้นไป ซึ่งถือว่าน่าพอใจสำหรับโมเดล 7B แต่ก็ยังถือว่าอยู่ในระดับทั่วไปสำหรับส่วนนี้
ปัจจุบัน MiMo-7B พร้อมใช้งานบน Hugging Face ภายใต้ใบอนุญาตโอเพนซอร์ส โดยสามารถตรวจสอบเอกสารประกอบและตรวจสอบรุ่นทั้งหมดได้บน GitHub
ที่มา gizmochina
Comment