
Google Research โชว์งานวิจัย Lumiere โมเดล AI ตัวใหม่สำหรับสร้างคลิปวิดีโอจาก promt ข้อความและรูปภาพ (text-to-video และ image-to-video) โดยมีจุดเด่นคือกระบวนการสร้างวิดีโอแบบราบรื่นในขั้นตอนเดียวด้วยสถาปัตยกรรม Space-Time U-Net หรือ STUNet ซึ่งแตกต่างจากโมเดล AI ตัวอื่นที่เป็นการสร้างวิดีโอแบบเฟรมต่อเฟรม
แม้จะกล่าวรวม ๆ ว่า Lumiere นั้นเป็น AI สำหรับสร้างคลิปวิดีโอ แต่ความสามารถจริง ๆ ของ Lumiere ยังแยกย่อยออกไปอีกหลายอย่าง ยกตัวอย่างบางส่วนตามที่ Google นำเสนอ ดังนี้
Text-to-Video
สร้างวิดีโอโดยการป้อนอินพุตเป็นข้อความ ลักษณะเดียวกับเครื่องมือ Image Creator ใน Bing ของ Microsoft หรือฟีเจอร์ Generative AI wallpaper ในมือถือ Pixel 8 และ Pixel 8 Pro ของ Google เพียงแต่ผลลัพธ์ของ Lumiere จะออกมาเป็นวิดีโอ ไม่ใช่รูปภาพ

Image-to-Video
สร้างวิดีโอโดยอาศัยภาพนิ่งเป็นข้อมูลตั้งต้น แล้วป้อนอินพุตเป็นข้อความในสิ่งที่ต้องการให้ภาพเคลื่อนไหว เช่น จากภาพแมวเกาะอยู่บนเปียโน แล้วใส่อินพุตว่า ‘A cat playing the piano’ ก็จะได้วิดีโอแมวกำลังดีดเปียโนในองค์ประกอบแบบเดียวกับภาพต้นฉบับ

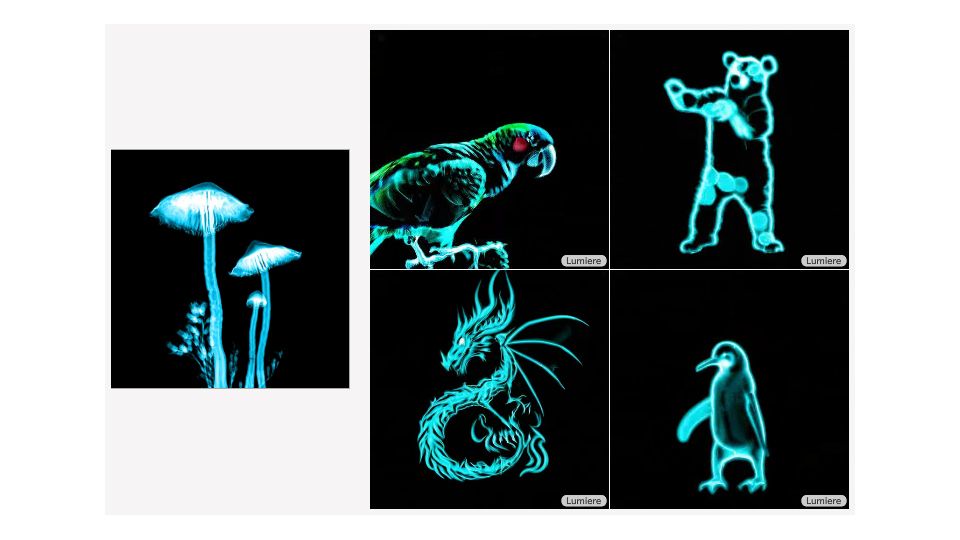
Stylized Generation
สร้างวิดีโอโดยการเลียนแบบสไตล์ศิลป์ของภาพต้นฉบับ
Video Stylization
เปลี่ยนสไตล์ศิลป์ในวิดีโอต้นฉบับให้เป็นรูปแบบที่ต้องการโดยการป้อนอินพุตเป็นข้อความ

Cinemagraphs
เปลี่ยนภาพนิ่งให้เป็นภาพเคลื่อนไหวเฉพาะจุดตามที่กำหนด

Video Inpainting
เติมเต็มภาพส่วนที่ขาดหายไปในวิดีโอ

ขณะนี้ Lumiere ยังอยู่ในสถานะงานวิจัย (มีการตั้งข้อสังเกตว่า Google อาจพัฒนา Lumiere ต่อยอดมาจาก Imagen โมเดล AI สร้างวิดีโอจากข้อความตัวเก่าที่เปิดตัวไว้ตอนปี 2022) โดย Lumiere สามารถสร้างเอาต์พุตคลิปวิดีโอได้ที่ความยาว 5 วินาที อัตราเฟรม 16 เฟรมต่อวินาที (รวมทั้งวิดีโอจะมี 80 เฟรม) บนความละเอียด 128 x 128 พิกเซล
ที่มา : Lumiere
Comment